
As AI workloads continue to grow, requiring both substantial data processing and rapid data movement between compute nodes, scaling AI models has become a critical challenge for modern infrastructures.
The need for cost-efficient and high-performing networks is becoming increasingly important, especially within HPC clusters.
This is where RoCE (RDMA over Converged Ethernet) becomes crucial. Let’s delve into why RoCE has become a widely adopted solution for managing AI workloads in 2024.
What is RoCE (RDMA over Converged Ethernet)?
RoCE is a network protocol that enables RDMA capabilities over Ethernet networks, allowing applications to directly access the memory of remote servers without involving their OS or CPU. This significantly reduces overhead and improves performance.
It does this by encapsulating the InfiniBand RDMA transport packet, enabling businesses to leverage Ethernet infrastructure as its transport mechanism, thus avoiding the need to invest in expensive InfiniBand infrastructure.
There are two versions of RoCE: RoCEv1 and RoCEv2.
RoCEv1 is a link-layer protocol, limiting its operation to devices within the same broadcast domain.
In contrast, RoCEv2 is an internet-layer protocol with UDP/IP headers, allowing for layer 3 routing and extending the capabilities of RDMA across subnets.
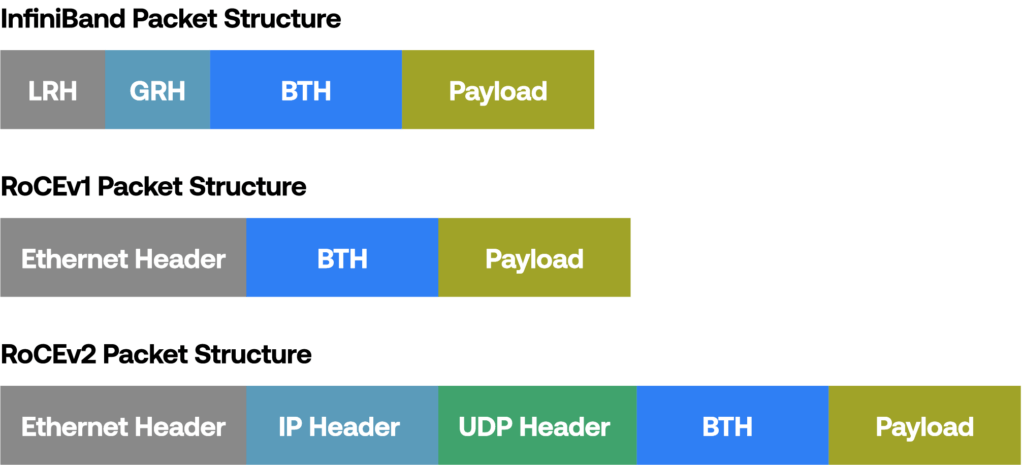
Fig. InfiniBand vs RoCEv1 and RoCEv2 packet structure. The Base Transport Header (BTH) is present in all three and is essential for RDMA control.
Breaking Down the Acronym
- RDMA (Remote Direct Memory Access): RDMA allows applications to directly access the memory of remote servers, bypassing the CPU and operating system. This eliminates the traditional data transfer process, which involves multiple processing steps, significantly reducing latency.
- Converged Ethernet (CE): It merges data and traditional Ethernet traffic onto a single network infrastructure while offering the flexibility to handle various data types.
Key Features of RoCE
- Kernel Bypass: RoCE leverages specialized NICs with RDMA capabilities. These NICs can directly access server memory, bypassing the CPU and operating system for data transfer tasks.
- Workload Offloading: By offloading data movement tasks from the CPU to the RDMA-enabled NICs, RoCE frees up valuable CPU resources. This allows the CPU to focus more on core computations.
- Data Streamlining: RoCE utilizes specialized protocols like User Datagram Protocol (UDP) for data transfer.
UDP prioritizes speed over error correction, making it ideal for high-throughput applications like AI where real-time data exchange is crucial.
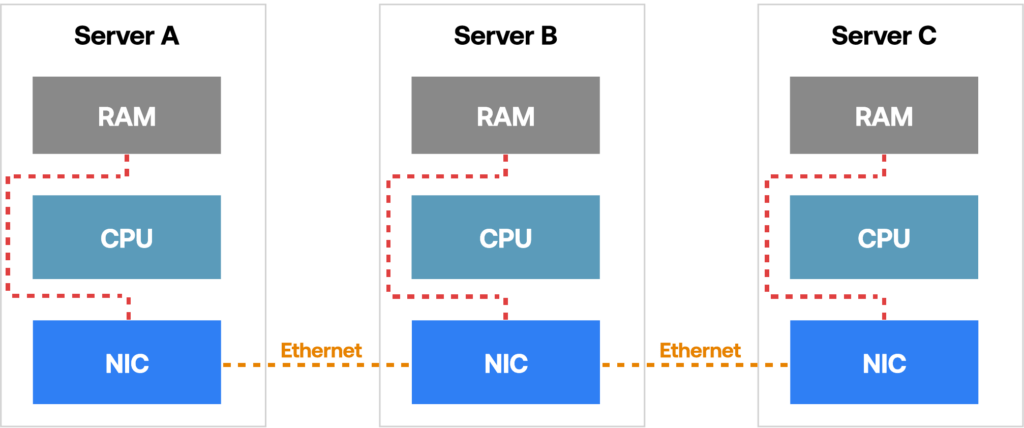
Fig. RoCE Data Flow Diagram.
Role of RoCE for AI Workloads
A. Low-latency data access
- Low-latency data access is essential in AI workloads, particularly for real-time processing tasks like natural language processing (NLP), image recognition, and autonomous vehicle control where the bulk of data is transferred.
- RoCE allows data to be transferred directly between the memory of one system and another without involving the CPU or operating system, which significantly reduces data access latency.
- By bypassing traditional networking layers, RoCE minimizes latency up to microseconds, helping AI algorithms to achieve faster inference and decision-making.
B. High bandwidth capabilities
- RoCE leverages the high speed and scalability of Ethernet networks to provide efficient data transfer for AI workloads.
Unlike traditional Ethernet, which may be limited in bandwidth and prone to congestion, RoCE enables data transfer rates of tens or hundreds of gigabits per second.
- By maximizing network bandwidth, RoCE ensures that AI algorithms can access large datasets and process them efficiently without being bottlenecked by network limitations. This high bandwidth is essential for tasks like deep learning model training, which often requires processing massive amounts of data.
C. Scalability for large datasets
- RoCE supports the scalability of AI infrastructure by enabling efficient communication between distributed nodes. It allows organizations to seamlessly scale their computational resources by adding more compute nodes, accelerators, or storage systems to accommodate growing datasets.
- Additionally, RoCE’s support for RDMA ensures that as the size of the dataset increases, data access latency also remains low. This helps in maintaining both the performance and responsiveness across the distributed AI system.
- RoCE works with existing Ethernet infrastructure, eliminating the need for new expensive specialized hardware. This helps in significant cost savings compared to other high-performance networking solutions.
- Further, RoCE can reduce the number of servers required, thereby promoting energy savings and reducing the footprint of Ethernet-based data centers.
D. Support for GPU-to-GPU communication
- GPUs play a crucial role in accelerating AI workloads, especially training models, due to their parallel processing capabilities.
- RoCE provides native support for GPU-to-GPU communication, allowing GPUs in different nodes within a cluster to exchange data directly without involving the CPU or host memory. This capability, known as GPU Direct RDMA, maximizes GPU utilization and minimizes data transfer latency.
- By enabling efficient GPU-to-GPU communication, RoCE enhances the performance of distributed AI applications (such as parallel model training or collaborative inference tasks) by reducing communication overhead and accelerating data exchange between GPUs.
E. Reduced CPU Overhead
- Traditional networking protocols, such as TCP/IP, require CPU involvement for data transfer, including packet processing, error handling, and protocol stack management.
- RoCE offloads these tasks to the network interface card (NIC), reducing CPU overhead and freeing up computational resources for AI processing tasks.
- By minimizing CPU involvement in data transfer, RoCE enhances overall system performance and efficiency, particularly in high-throughput AI workloads where CPU resources are critical.
F. Deterministic Performance
- RoCE advantage of PFC (Priority Flow Control) in DCB Ethernet for deterministic performance. Its low-latency, high-bandwidth capabilities ensure consistent data transfer rates and response times, enabling AI algorithms to meet strict timing requirements, such as real-time decision-making or sensor data processing.
- Deterministic performance is particularly valuable in safety-critical AI systems, such as autonomous vehicles or medical diagnostics, where predictability and consistency are essential and deviations in data processing latency can have significant consequences.
G. QoS Support
- RoCE networks often incorporate Quality of Service (QoS) mechanisms to prioritize traffic based on application requirements.
- QoS support ensures that critical AI workloads receive preferential treatment in terms of network bandwidth and latency, guaranteeing consistent performance even in shared network environments.
- By providing QoS capabilities, RoCE enables organizations to optimize network resources for different types of AI workloads, balancing performance, and resource allocation based on application priorities.
H. Security and Data Integrity
- Encryption mechanisms, such as IPsec or Datagram Transport Layer Security (DTLS), ensure secure communication over RoCE networks, safeguarding sensitive AI data from unauthorized access or tampering.
- Additionally, RoCE’s support for Remote Direct Memory Protection (RDMP) ensures data integrity by validating data transfers and detecting any anomalies or corruption during transmission.

Table. Traditional Network Communication vs RoCE.
Key Considerations
While RoCE offers significant benefits for AI workloads, it’s essential to evaluate its suitability for your specific needs. Here are some factors to consider:
- Network Traffic Patterns: RoCE excels at high-throughput, low-latency data transfers primarily between servers within a data center. If your AI model involves significant communication with external devices, RoCE might not be the sole solution.
- Existing Infrastructure: Utilization of existing Converged Ethernet (CE) infrastructure is a significant advantage of RoCE. However, if your network doesn’t support CE, implementing RoCE will require additional hardware investments.
- Network Infrastructure Compatibility: Ensure that your existing network infrastructure, including switches, routers, and NICs, supports RoCE. RoCE requires Ethernet switches that are capable of handling lossless traffic and Priority Flow Control (PFC) to prevent packet loss and ensure reliable data transmission.
Conclusion
RoCE is a powerful network protocol and technology for businesses investing in AI infrastructure. By enabling RDMA’s low latency and high bandwidth capabilities over existing Ethernet infrastructure, RoCE maximizes hardware utilization and cost efficiency by improving network performance.
This results in the acceleration of parallel AI workload processing, directly translating to faster model training and inference, quicker insights from data, and ultimately, a competitive edge in industries increasingly driven by AI.
References
- Patel, N. (n.d.). AI’s role in network management. D-Link. Link
- Cisco. (n.d.). What Is Artificial Intelligence in Networking? Link
- Sasidharan, S. (2024). What is AI for Network Management and Control? ThinkPalm. Link
- IEEE. (2007). System of Systems Management: A Network Management Approach. IEEE Xplore. Link
- Oracle. (2023). What Is AI Model Training & Why Is It Important? Link
- Plumb, T. (n.d.). What is AI networking? Use cases, benefits and challenges. SDxCentral. Link
- Pal, S. (2024). Future Trends of AI-driven Network Optimization. Link
- RDMA [1]: A short history of remote DMA networking. Link
- InfiniBand Architecture Overview. Link
- Remote Direct Memory Access (RDMA). Link
About Hardware Nation:
Hardware Nation is a professional services company that accelerates network transformation through a disaggregated, open approach, enabling freedom of choice, flexibility, and cost efficiency. Our seasoned experts have worked on projects for some of the world’s leading organizations, leveraging a hybrid cloud-first and AI-enabled approach. We help our customers navigate the ecosystem, drawing on decades of experience. Our deployments are powered by leading white box and OEM network, compute, and storage vendors. Our expertise encompasses a wide range of industries and use cases, including enterprise, cloud, data center, AI, 5G/ISP infrastructure, and edge IT.
Humza Atlaf
Network Engineer
Humza is a network engineer at Hardware Nation Labs, where his enthusiasm for Open Networking drives his work. With a blend of deep expertise and innovative approaches, he designs robust, scalable networks of the future. His practical experience includes configuring and deploying a range of protocols such as LACP, VLANs, MPLS, and VRRP. At his previous role, he was part of a SONiC testing team, further honing his skills in network setup and troubleshooting. Humza is also adept at network analysis with tools like Wireshark, enhancing his ability to manage complex network environments.
Rahul Narwal
Content Writer
Rahul is a content writer passionate about AI and software development, blending creativity with technical expertise. He creates engaging articles, visuals, and research papers in collaboration with seasoned experts, simplifying complex topics for both technical and non-technical audiences.
Alex Cronin
Co-Founder and Solutions Architect
Alex Cronin is a seasoned Solutions Architect with over 15 years of experience in networking and disaggregated infrastructure. His career is defined by aligning enterprise technology with business needs across diverse market segments, from emerging startups to Fortune 500 companies. He has worked on digital infrastructure projects covering network design and software solutions for data center operators, service providers, and enterprises. He is continuously collaborating with Hardware Nation Labs R&D to explore and pioneer the latest advancements in open networking and is assessing the applicability of AI/ML technology across enterprise, data center, and service provider infrastructures.



